Container Monitoring
-
Container에서 실행하는 애플리케이션에 있어, 투명성은 매우 중요한 요소이다.
-
투명성을 확보하지 못한다면, 애플리케이션이 뭘 하고 있는지 또는 어떤 상태에 있는지 문제가 있다면 어떤 부분이 원인인지 조차 알 수 없다.
-
프로메테우스를 사용해 애플리케이션 컨테이너에서 측정된 수치를 수집하고 그라파나를 사용해 수치를 시각화해 이해하기 쉬운 대시보드 형태로 구성한다.
-
이들 도구는 오픈 소스이며, 여러 플랫폼에서 사용할 수 있다.
-
그러므로 개발 환경과 운영환경을 막론하고 어떤 환경에서도 동등하게 애플리케이션 성능을 확인 할 수 있다.
컨테이너 화 된 애플리케이션에서 사용되는 모니터링 기술 스택
-
컨테이너 환경의 모니터링은 일반 환경과는 사뭇 다르다.
-
컨테이너 이전의 전통적인 애플리케이션 모니터링이라고 하면, 서버의 목록과 현재 동작 상태(잔여 디스크 공간, 메모리와 CPU 사용량 등)가 표시된
-
대시보드가 있고, 과부하 걸리거나 응답하지 않는 서버가 발생하면 경보가 울리는 형태가 대표적이다.
-
컨테이너화 된 애플리케이션의 환경은 이 보다 훨씬 역동적이다.
-
애플리케이션은 수십 개에서 수백 개에 이르는 컨테이터에 걸처 실행되고, 컨테이너는 플랫폼에 의해 끊임없이 생성됐다가 삭제되기를 반복한다.
-
이런 환경에서는 컨테이너를 다룰 수 있으며, 컨테이너 플랫폼과 연동해 정적인 컨테이너 혹은 IP 주소 목록 없이도 실행 중인 플랫폼과 연동해 정적인 컨테이너 혹은 IP 주소 목록 없이도 실행중인 애플리케이션을 속속들이
-
들여다 볼 수 있는 도구를 갖춘 새로운 모니터링 방식이 필요하다.
-
프로메테우스가 바로 이런 기능을 제공하는 오픈 소스 도구이다.
-
프로메테우스는 CNCF(K8S 컨테이너 런타임인 containerd를 관리하는 곳)에서 개발을 담당하여 다양한 곳에서 널리 사용되고 있다.
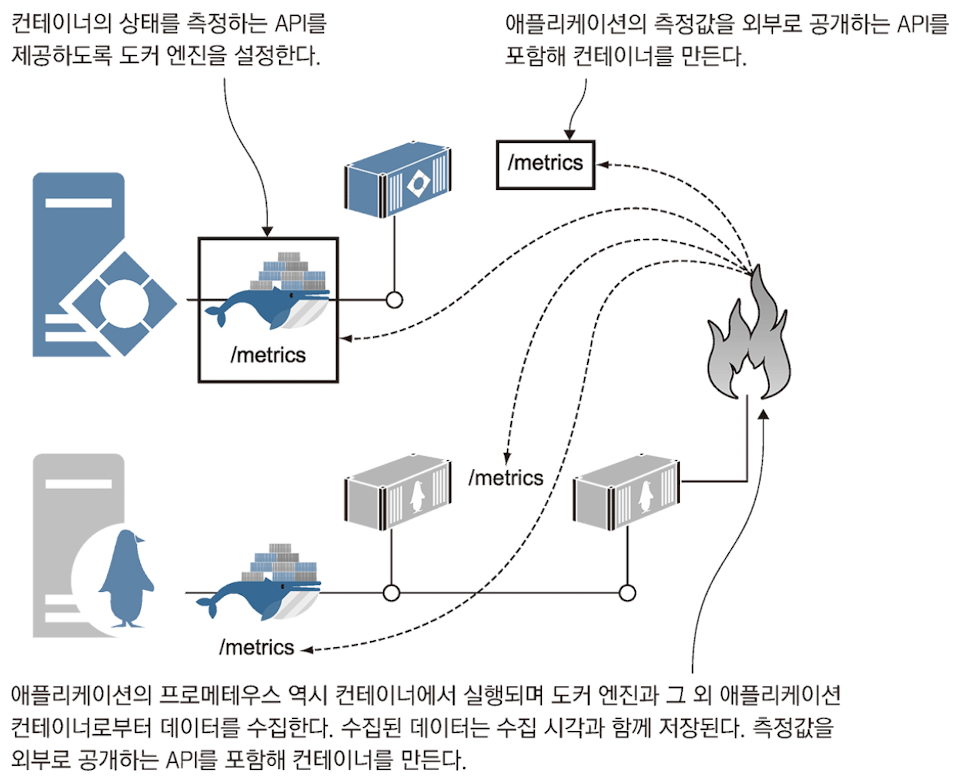
- 프로메테우스를 사용하면, 모니터링의 중요한 측면인 일관성이 확보된다.
- 모든 애플리케이션에서 똑같이 구성된 측정 값을 내놓기 때문에, 모든 애플리케이션을 똑같은 표준적인 형태로 모니터링이 가능하다.
- 측정값을 추출하기 위한 쿼리 언어도 한가지만 익히면 되고, 전체 애플리케이션 스택에 똑같은 모니터링을 적용할 수 있다.
- docker engine의 측정값도 같은 형식으로 추출 가능
- docker engine의 설정 해주어야한다.
/etc/docker/daemon.json을 아래와 같이 수정하면 된다.
{
"metrics-addr" : "0.0.0.0:9323",
"experimental" : true
}
-
해당 설정을 추가하면 9323포트를 통해 측정 값이 공개된다.
-
해당 기능은 실험적 기능이지만(언제든지 변동 가능성 존재) 하지만, 별다른 변동 없이 유지 중이다.
-
해당 기능을 활성화 했다면,
localhost9323/metrics에서 도커 엔진의 상태 정보를 볼 수 있다.

-
지금 본 상태 정보 출력 포맷이 프로메테우스 포맷이다.
-
측정된 각 상채 정보가 이름과 값의 쌍 형태로 표현되는 간단한 텍스트 기반 포맷으로 돼 있다.
- 이름-값 쌍 앞에는 해당 정보가 어떤 정보인지, 값의 데이터 타입은 무엇 인지에 대해 간단한 아낸 설명이 붙는다.
-
이 텍스트 형식의 정보가 컨테이너 모니터링의 핵심이다.
-
정보 항목마다 별도의 엔드포인트를 통해 실시간으로 값을 제공한다.
-
프로메테우스는 이 값을 수집하면서 타임 스탬프 값을 덧 붙여 저장하므로 저장된 값을 정리해 시간에 따른 값의 변화를 추적할 수 있다.
- 프로메테우스를 컨테이너에서 실행해 현재 docker를 실행 중인 컴퓨터의 정보를 수집해보자
# 로컬 컴퓨터의 IP 주소를 확인해 환경 벼수로 정의하기(리눅스)
$hostIP = $(Get-NetIPConfigure | Where-Object {$_.IPv4DefaultGateway-ne})
# 로컬 컴퓨터의 IP 주소를 확인해 환경 변수로 정의하기(리눅스)
hostIP = $(ip route get 1 | awk '{print $NF;exit}')
# 로컬 컴퓨터의 IP주소를 확인해 환경 변수로 정의하기(macOS)
hostIP=$(ifconfig ebn0 | grep -e 'init\s')
# 환경 변수로 로컬 컴퓨터의 IP 주소를 전달해 컨테이너를 실행
docker container run -e DOCKER_HOST=$hostIP -d -p 9090:9090 diamol/prometheus:2.13.1
- 프로메테우스가 포함된 diamol/Prometheus 이미지의 설정 중 DOCKER_HOST 환경 변수를 사용해 호스트 컴퓨터와 통신하고 docker engine 상태 측정값을 수집한다.
- 컨테이에서 호스트 컴퓨터의 서비스에 접근 할 일은 별로 없지만, 필요하다면 서버 이름을 설정해 Docker가 IP 주소를 직접 알아내도록 한다.
- 개발 환경이라면 이런 방법을 쓰기 어려울 수도 있으니 IP 주소를 직접 전달하면 된다.
- 프로메테우스가 실행 됐다.
- 주기적으로 docker host에서 측정값을 수집한 다음, 타임 스탬프를 덧붙여 데이터베이스 저장한다.
- 그리고 수집된 데이터를 열람할 수 있는 간단한 웹 인터페이스가 실행됐다.
- 이 웹 인터페이스를 통해 /metrics 엔드포인트로 제공되는 정보는 모두 확인 할 수 있다.
- 원하는 정보만 필터링 하거나 표 혹은 그래프 형식으로 요약해 보는 것도 가능하다.
-
웹 인터페이스 메뉴의 Status > Targets 항목에서 원하는 대상의 DOCKER_HOST의 상태가 녹색이라면 프로메테우스가 호스트 컴퓨터를 발견했다는 뜻이다.
-
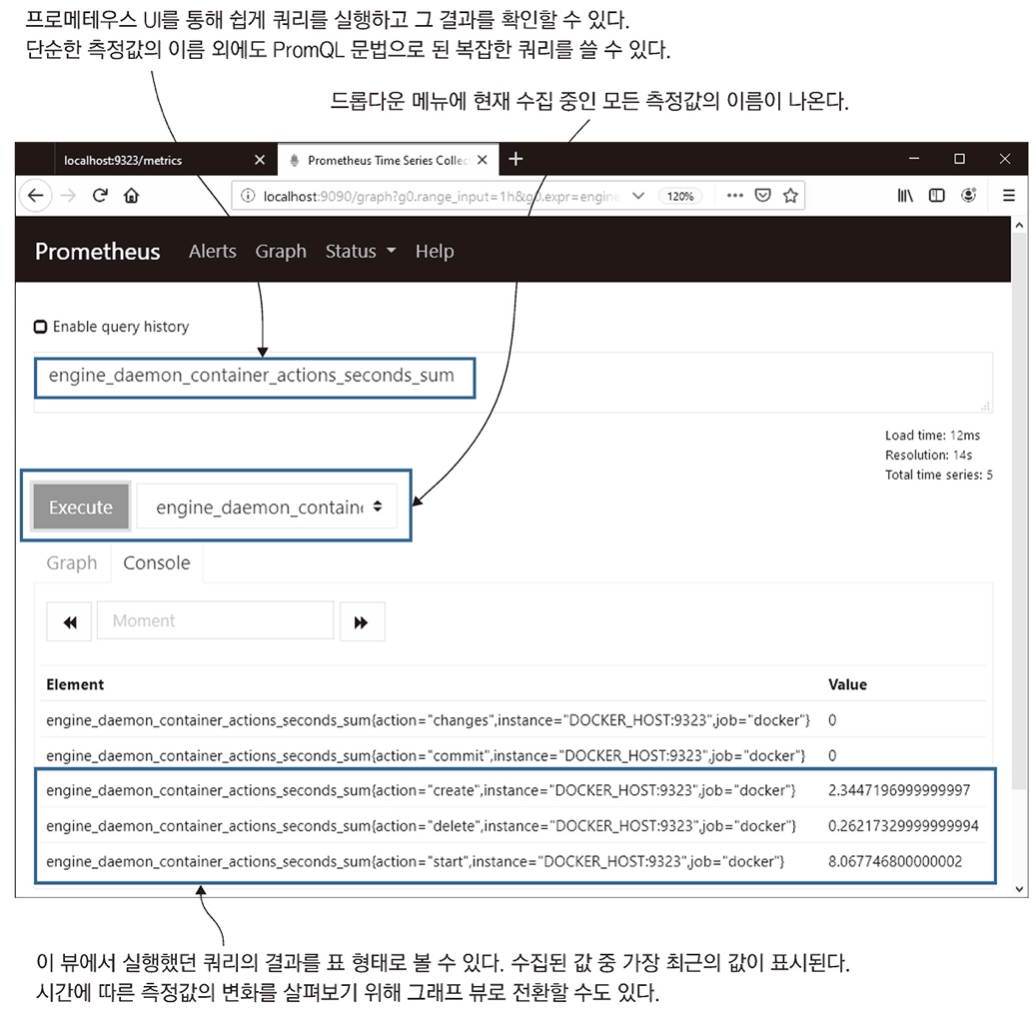
그 다음 Graph 메뉴로 이동하면 프로메테우스가 수집한 모든 측정값의 목록이 담긴 드롭다운 리스트가 나온다.
-
그 중에는
engine_daemon_container_actions_seconds_sum이라는 항목은 컨테이너의 각 활동에 걸린 시간을 의미한다. -
이 항목을 선택하고 Execute버튼을 클릭하면 아래와 같이 비슷한 화면을 볼 수있다.
-
이 화면에서 컨테이너를 시작, 생성, 삭제하는데 걸린 시간이 각각 얼마나 되는지 알 수 있다.
-
프로메테우스의 웹 인터페이스를 통하면 어떤 정보가 수집 됐는지 일목요연 하게 볼 수도 있고, 간단한 쿼리를 사용할 수도 있다.
-
이들 정보는 각 상태별 컨테이너 수나 실패한 헬스 체크 횟수 같은 고 수준 정보부터 docker 엔진이 점유 중인 메모리 용량 같은 저 수준 정보까지 다양하다.
-
호스트 컴퓨터에 설치된 CPU 수와 같은 Infrastructure 의 정정인 정보도 여기에 포함 된다.
-
이들 정보도 dashboard에 포함 시킨다면, 유용하게 활용할 수 있다.
-
애플리케이션 또한 자신의 상태 정보를 제공하는데, 이들 정보의 자세한 정도는 애플리케이션 마다 다르다.
-
우리가 할일은 컨테이너마다 측정값을 수집할 엔드포인트를 만들고, 프로메테우스가 이들 엔드포인트에서 주기적으로 정보를 수집하게 하는 것이다.
-
이 정도면 전체 시스템의 상태를 한눈에 알 수있는 dashboard를 만드는데 충분한 정보를 수집할 수 있다.
애플리케이션의 측정값 출력하기
- 앞서 docker engine이 출력하는 측정 값을 살펴 봤다.
- docker engine 측정값은 프로메테우스의 사용법을 익히는 출발점으로 적당하기 때문이다.
- 애플리케이션의 유용한 정보를 측정값으로 구성하려면 이들 정보를 생성하는 코드를 작성해 HTTP 엔드포인트로 출력해야 하기 때문에, 이미 만들어진 Docker Engine의 측정값을 수집하는 것보다는 좀 더 수고가 필요하다.
- 하지만 프로그래밍 언어에서 프로메테우스의 라이브러리가 제공되므로 어렵진 않음
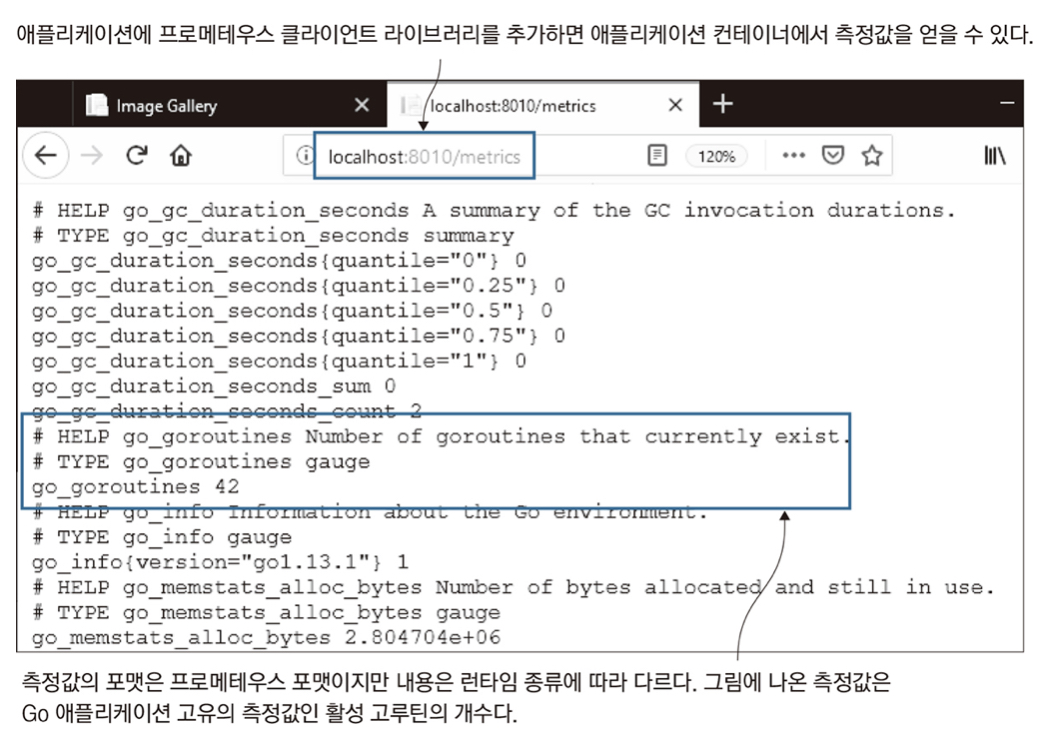
!IMG_4982DF45BE74-1.jpeg - 프로메테우스 클라이언트 라이브러리를 통해 수집된 정보는 런타임 수준의 측정값으로, 해당 컨테이너가 처리하는 작업이 무엇이고 이 작업의 부하가 어느 정도 인지에 대한 정보가 런테임의 관점에서 표현돼 있다.
- 예를 들어 Go 애플리케이션의 측정값에는 현재 활성 상태인 고루틴의 개수가 포함돼 있고, 자바 애플리케이션의 측정값에는 JVM이 사용 중인 메모리 용량 정보가 들어 있다.
- 각각의 런타임은 자신만의 중요도가 높은 측정값을 갖고 있으며 해당 클라이언트 라이브러도 이러한 정보를 수집해 외부로 제공한다.
cd ./ch09/exercises
# 모든 컨테이너를 제거한다.
docker container rm -f $(docker container ls -aq)
# 도커 네트워크 nat을 생성한다.
# 같은 이름의 기존 네트워크가 있다면, 경고 메시지가 나오지만, 무시해도 좋다.
docker-compose up -d
# 웹 브라우저에서 http:localhost:8081에 접근하면 애플리케이션 화면이 나타난다.
# http://localhost:8010/metrics에서 측정값을 볼 수있다.
-
웹 브라우저에서 http://localhost:8011/actuator/prometheus에 접근하면 이와 비슷한 형태로 Java REST API의 측정값을 볼 수 있다.
-
엔드포인트에서 출력된 내용은 언뜻 어수선한 텍스트 처럼 보이지만, 그 안에 컨테이너가 얼마나 동작하는지 한눈에 알 수 있다.
-
이러한 런타임 상태 측정값은 docker 엔진에서 얻은 infrastructure 측정값과는 또 다른 수준의 정보를 제공한다.
-
하지만, 이 두 수준의 정보만으로 알 수 없는 것도 있다.
- 측정값의 마지막 수준은 애플리케이션에서 우리가 직접 노출 시키는 핵심 정보로 구성된 애플리케이션 측정 값이다.
-
애플리케이션 측정값은 컴포넌트가 처리하는 이벤트의 수, 평균 응답 처리 시간처럼 연산 중심의 정보일 수도, 현재 시스템을 사용 중인 활성 사용자 수나 새로운 서비스를 사용하는 사용자 수와 같이 비즈니스 중심의 정보일 수도 있다.
-
프로메테우스 클라이언트 라이브러리를 사용해도 이러한 애플리케이션 측정값을 수집할 수도 있다.
-
하지만, 이러한 정보를 수집하기 위해서는 애플리케이션에서 명시적으로 이들 정보를 생성하는 코드를 작성해야한다.
-
아래는 NodeJS에서 프로메테우스 라이브러리를 access-log 컴포넌트에서 사용한 예이다.
// 측정값 선언
const accessCounter = new prom.Counter({
name: "access_log_total",
help: "Access Log - 총 로그 수"
});
const clientIpGauge = new prom.Gauge({
name: "access_client_ip_current",
help: "Access Log - 현재 접속 중인 IP 주소"
});
// 측정값 갱신하기
accessCounter.inc()
clientIpGauge.set(countOfIpAddresses);
-
이번 장의 예제 코드를 보면, Go 언어로 구현된
image-gallery애플리케이션과 Java로 구현된 REST API image-of-the-day 애플리케이션에 내가 정의해 추가한 측정 값을 볼수 있을 것이다. -
두 애플리케이션에 내가 정의해 추가한 측정값을 볼 수 있을 것이다.
-
두 애플리케이션에서 프로메테우스 클라이언트 라이브러리는 서로 다른 방식으로 동작한다.
-
main.go 파일에서도 NodeJS 소스 코드에서 처럼 먼저 카운터와 게이지를 초기화하지만, 그 다음에는 측정값을 명시적으로 갱신하지 않고, 라이브러리에서 제공되는 핸들러로 처리한다.
-
Java Application에서 사용된 방식은 이와는 또 다르다.
-
ImageController.java파일을 보면@Timed어노테이션과 registry.counter 객체를 증가시키는 방식을 사용했다. -
두 클라이언트 모두 해당 언어에서 가장 합리적인 방식으로 동작한다.
-
프로메테우스의 측정값에도 몇 가지 유형이 있다.
-
이 애플리케이션에서 사용한 유형은 그 중에서도 가장 간단한 종류인 카운터와 게이지다.
-
카운터와 게이지는 모두 숫잣값인데, 카운ㅌ터의 값은 현상 유지 혹은 증가만 가능하고 게이지의 값은 증가와 감소 모두 가능하다.
-
가장 적합한 측정값 유형을 정하고 정확한 시점에 값을 갱신하는 것은 독자 여러분, 즉 애플리케이션 개발자에게 달렸다.
-
나머지는 프로메테우스 라이브러리가 대신 처리해준다.
- 애플리케이션에 조금 부하를 가한 다음, 해당 애플리케이션의 측정ㄱ밧이 출력되는 엔드포인트에 접근해보자
# 반복문을 돌려 다섯번의 HTTP GET 요청을 보낸다.(윈도)
for($i=1; $i -le 5; $i++){ iwr -useb http://lcoalshot:8010 | Out-Null }
# 반복문을 돌며 다섯 번의 HTTP GET 요청을 보낸다.(리눅스)
for i in {1..5}; do curl http://localhost:8010 > /dev/null; done
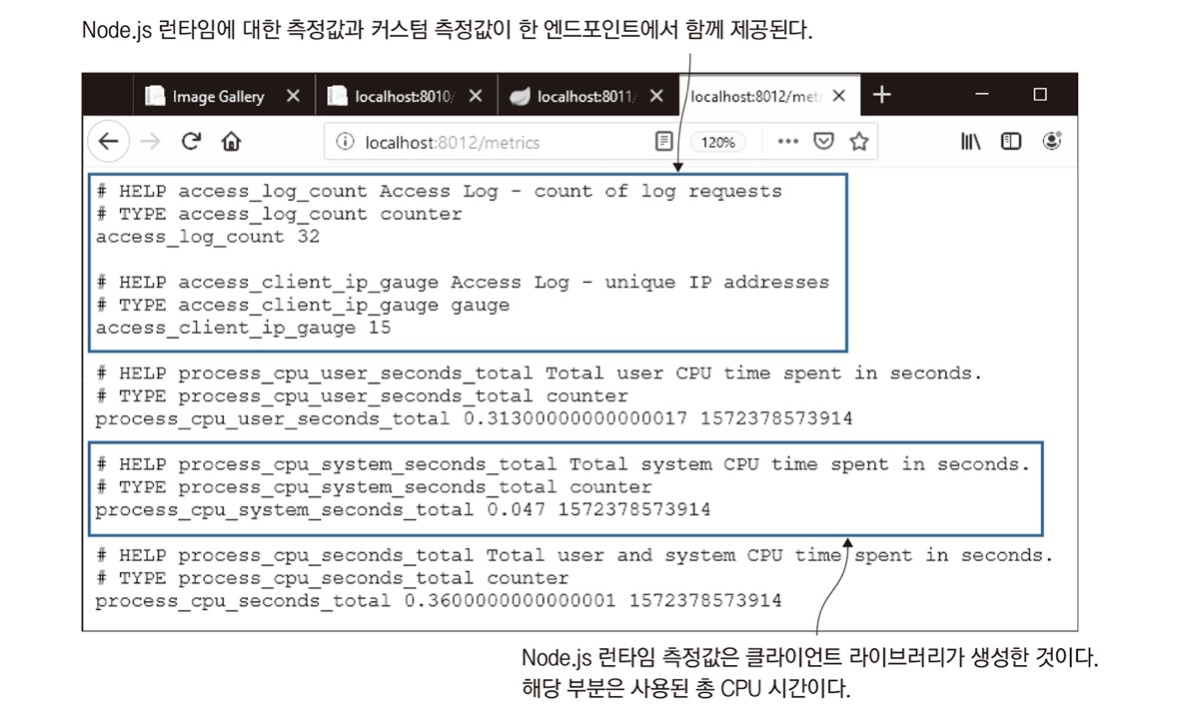
# 웹 브라우저에서 http://localhost:8012/metrics에 접근한다.
- 이 명령을 실행한 후 몇 차례 더 API에 요청을 보냈다.
- 처음 두 개의 레코드는 내가 추가한 커스텀 측정값으로, API에 들어온 요청의 횟수와 서비스를 이용한 IP 주소의 총개수를 기록한 것이다.
- 간단한 측정값이지만(그나마 IP 주소의 총개수를 기록한 것이다.)
- 간단한 측정값이지만(그나마 IP 주소의 수는 실제 값도 아니다.)
- 측정값을 수집한다는 목적은 충분히 달성했다.
- 프로메테우스를 사용해 이보다 더 복잡한 측정값도 수집할 수 있다.
- 하지만 간단한 카운터나 게이지 같은 측정값으로도 애플리케이션의 상세한 상황을 알 수있다.
- 어떤 값을 수집할지는 어떤 애플리케이션이냐에 따라 달라진다.
- 하지만 다음 목록을 대강의 기준으로 삼을 수 있다.
- 애플리케이션의 상세한 모니터링을 추가할 때 이 목록을 다시 참고해라
- (만약 있다면) 외부 시스템과의 통신에 걸린 시간과 성공적으로 응답을 받았는지 여부에 대한 기록
- 이 측정값으로 외부 시스템이 애플리케이션의 속도나 이상 상태에 영향을 줬는지 알 수 있다.
- 로그로 남길 가치에 있는 모든 정보.
- 로그로 남기는 것보다 측정값으로 수집하는 편이 메모리, 디스크 용량, CPU 시간 면에서 저렴하고, 추세를 볼 수 있도록 시각화하기도 쉽다.
- 사업 부서에서 필요로하는 애플리케이션의 상태 및 사용자 행동에 관한 모든 정보.
- 측정값을 활용하면 과거 정보를 수고를 들여 보고하는 대신 실시간 정보로 대시보드를 구성할 수 있다.
측정값 수집을 맡을 프로메테우스 컨테이너 실행하기
- 프로메테우스는 직접 측정값을 대상 시스템에서 받아다 수집하는 풀링 방식으로 동작한다.
- 프로메테우스에서 측정값을 수집하는 이 과정을 스크래핑이라고 한다.
- 프로메테우스를 실행하면 스크래핑 대상 endpoint를 설정해야 한다.
- 운영 환경의 컨테이너 플랫폼에서 클러스터에 있는 모든 컨테이너를 찾도록 설정할 수도 있다.
- 단일 서버의 docker compose 환경에서는 모든 서비스 목록으로 docker network DNS를 통해 대상 컨테이너를 자동으로 찾는다.
global:
scrape_interval: 10s
scrape_configs:
- job_name : "image-gallery"
metrics_path : /metrics
static_configs:
- targets:["image-gallery"]
- job_name: "iotd-api"
metrics_path: /actuator/prometheus
static_configs:
- tagets:["iotd"]
- job_name: "access-log"
metrics_path: /metrics
dns_sd_configs:
- names:
- accesslog
type: A
port: 80
- 위의 코드는 image-gallery 애플리케이션의 두 컴포넌트로부터 측정값을 스크래핑 하기 위해 설정했다.
- 전역 설정인 global 항목을 보면 스크래핑하기 위해 내가 사용한 설정이다.
- 전역 설정인 global항목을 보면 스크래핑 간격이 기본값이 10초로 설정돼 있고, 각 컴포넌트마다 스크래핑 작업을 의미하는 Job 설정이 정의 돼 있다.
- job 설정은 해당 스크래핑 작업의 이름과 측정값을 수집할 엔드포인트, 대상 컨테이너를 지정하는 정보로 구성된다.